Las claves que conviene fijar antes de avanzar
- La secuencia codificante es la parte del gen que puede traducirse en una proteína; no todo el genoma cumple esa función.
- En humanos, la información que codifica proteínas ocupa solo una fracción pequeña del genoma, en torno al 1,5 %.
- La lectura biológica se organiza en codones de tres bases y termina en un codón de parada.
- Exones e intrones no significan lo mismo: algunos exones son codificantes, pero otros contienen regiones no traducidas.
- Muchas variantes relevantes para la salud no cambian la proteína de forma directa, sino su procesamiento o su expresión.
Qué parte del gen realmente codifica proteína
Yo suelo empezar por una distinción sencilla: un gen no es solo la “receta final” de una proteína, sino un conjunto de instrucciones más amplio. Dentro de ese conjunto, la secuencia codificante es la porción que termina traducida a aminoácidos, es decir, la parte que define la estructura primaria de la proteína.
NHGRI resume bien esta idea: en humanos, alrededor del 1,5 % del genoma corresponde a genes que codifican proteínas. El resto incluye regiones reguladoras, intrones, secuencias repetidas y zonas cuya función se conoce a medias o aún se estudia. Esa cifra es útil porque corrige una intuición muy común: no todo el ADN “sirve para fabricar proteínas”, y tampoco todo lo que no codifica es irrelevante.
Además, un mismo gen puede dar lugar a más de una proteína mediante splicing alternativo, un proceso que combina exones de forma distinta según el tipo celular o el momento biológico. Por eso, cuando hablo de una región codificante, no pienso en una pieza aislada, sino en una parte del gen que funciona dentro de un sistema más amplio. Con ese marco claro, ya se entiende mejor cómo se lee esa información dentro de la célula.
Cómo se convierte una secuencia en proteína paso a paso
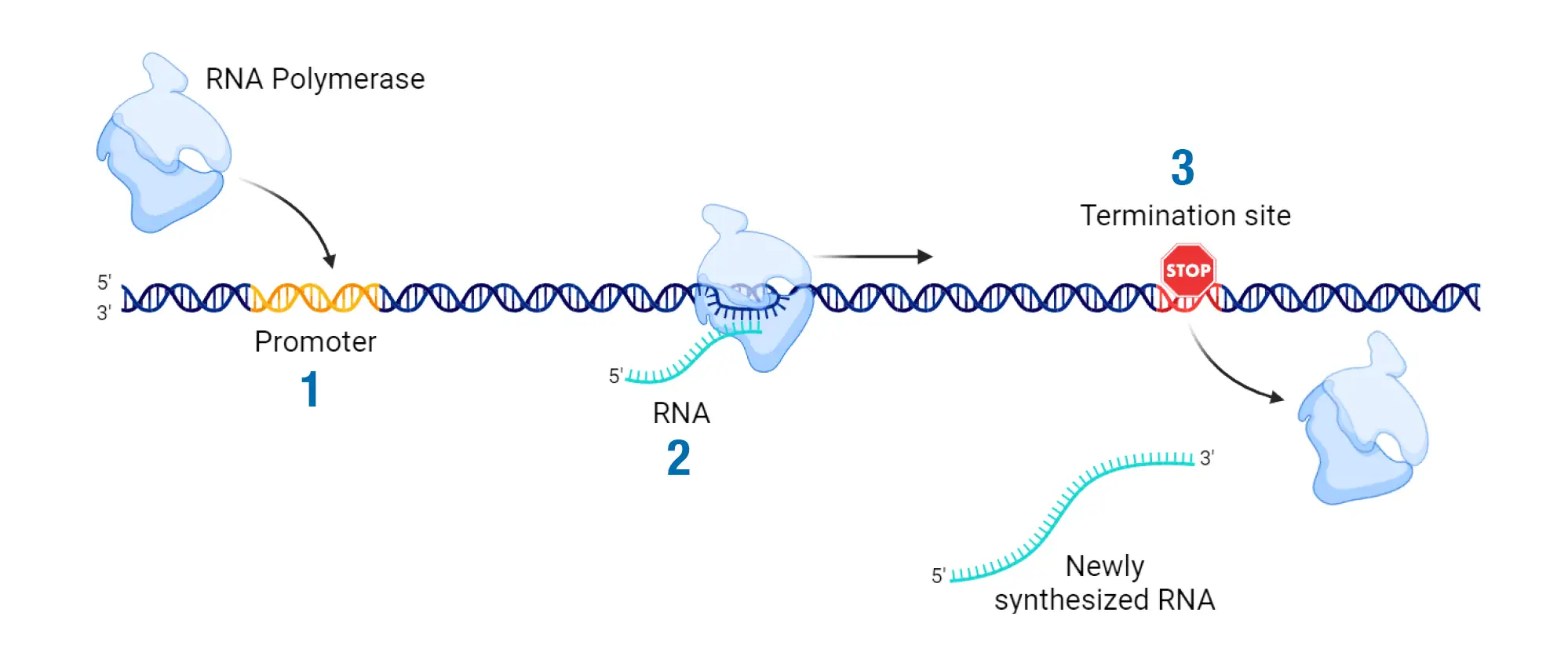
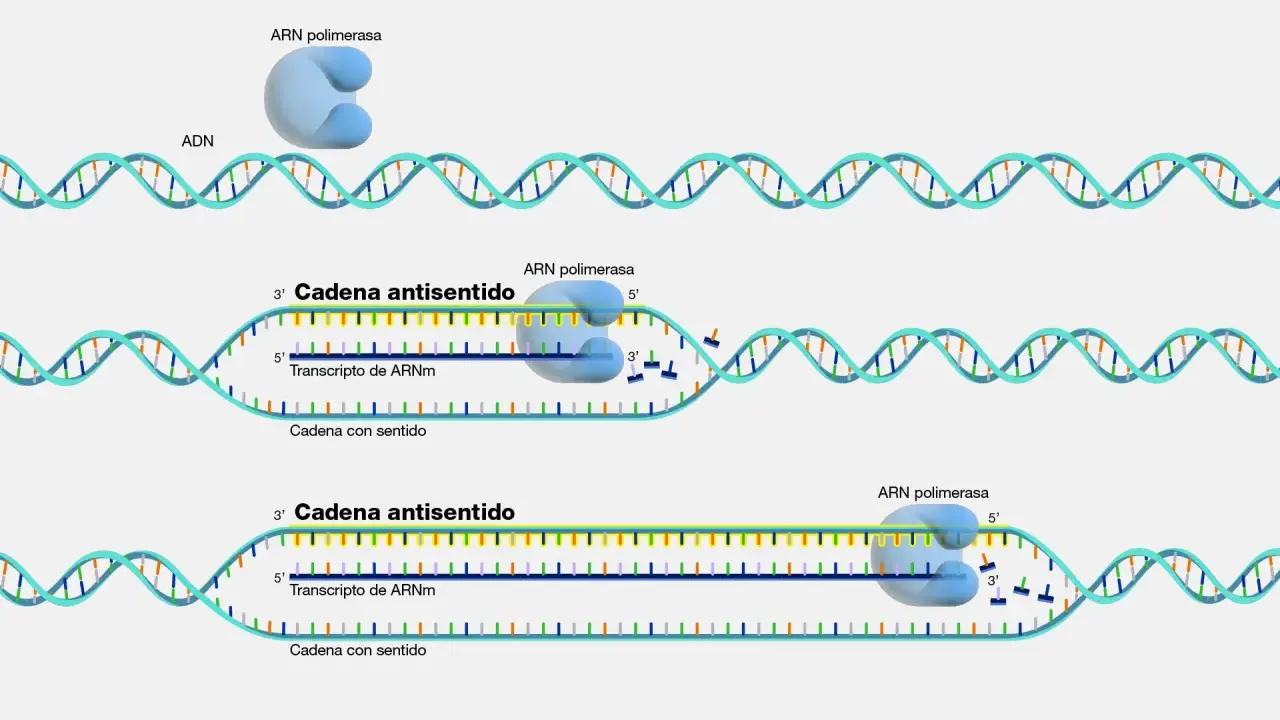
La biología molecular convierte la información del ADN en proteína siguiendo el flujo clásico ADN → ARN → proteína. Parece un recorrido lineal, pero en realidad hay varios controles intermedios que deciden si una secuencia llega o no a traducirse.
- Transcripción. El ADN del gen se copia en ARN mensajero (ARNm) dentro del núcleo celular.
- Procesamiento del ARN. En eucariotas, ese transcrito inicial se madura antes de salir al citoplasma; aquí entra el splicing, que elimina intrones y deja un ARNm funcional.
- Traducción. El ribosoma lee el ARNm de tres bases en tres bases. Cada triplete se llama codón, una unidad de tres nucleótidos que especifica un aminoácido o una señal de parada.
- Terminación. La traducción se detiene cuando aparece un codón de parada. De los 64 codones posibles, 61 codifican aminoácidos y 3 actúan como stop.
Hay dos términos que conviene separar con cuidado. Un codón es la tripleta concreta de bases; el marco de lectura es la forma correcta de agrupar esas tripletas desde el punto de inicio. Si el marco se desplaza, la proteína cambia por completo. Yo suelo fijarme también en el marco de lectura abierto (ORF), que es el tramo que puede leerse sin encontrar una parada prematura y que ayuda a identificar si una secuencia tiene capacidad real para codificar proteína. Con esto en mente, la siguiente confusión habitual ya se ve venir: exón no significa exactamente lo mismo que región codificante.
Exones, intrones y regiones reguladoras no son equivalentes
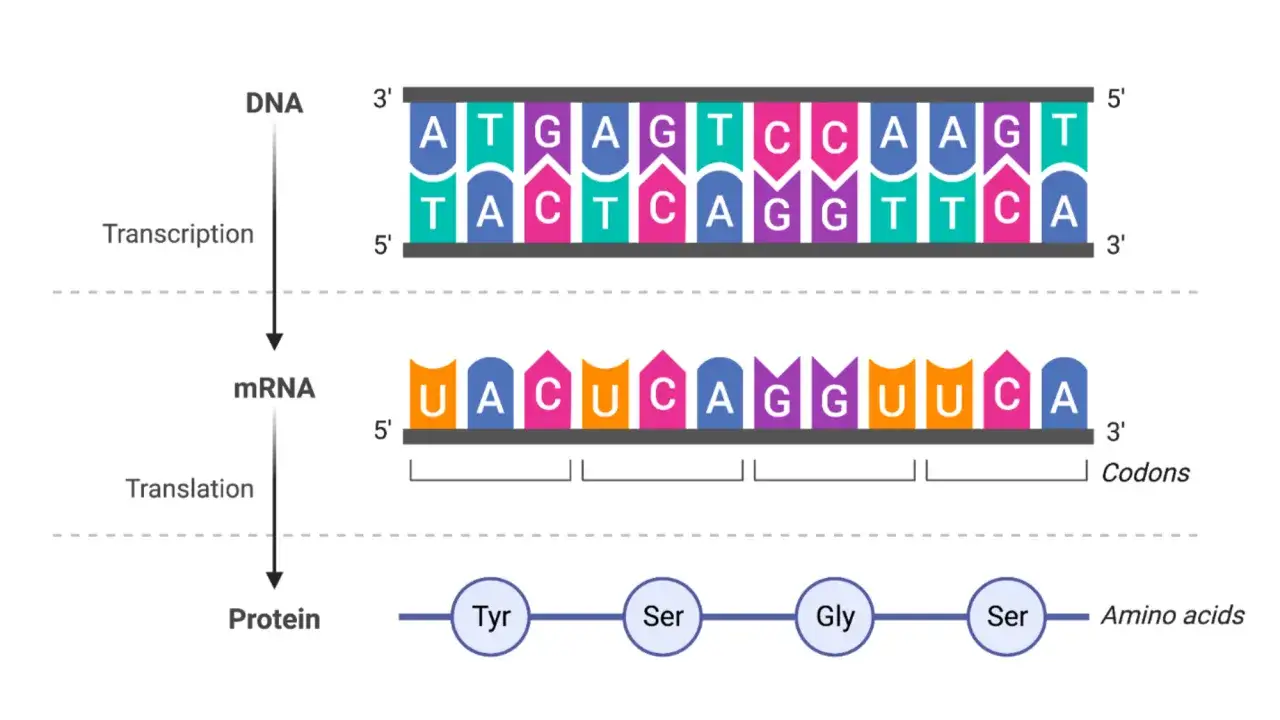
Esta es la zona donde más errores veo en divulgación y, a veces, también en informes genéticos. Un exón es una porción que permanece en el ARNm maduro, pero eso no implica que toda su longitud vaya a traducirse en proteína. Algunos exones contienen la parte codificante; otros incluyen las regiones no traducidas del ARNm, conocidas como UTR (untranslated regions), que no se convierten en aminoácidos pero sí influyen en la estabilidad, localización o eficiencia de traducción del mensaje.
MedlinePlus Genetics recuerda que los intrones se transcriben dentro de muchos genes codificantes, pero se eliminan antes de producir la proteína. Además, elementos como promotores y potenciadores pueden estar en lugares que no codifican aminoácidos y aun así controlar de forma decisiva la actividad del gen. Esa es la razón por la que una variante “fuera de la parte codificante” puede tener impacto biológico real.
| Elemento | ¿Se traduce? | Qué hace realmente |
|---|---|---|
| Región codificante | Sí | Define la secuencia de aminoácidos de la proteína. |
| Exón | A veces | Permanecerá en el ARNm maduro; puede contener parte codificante y también UTR. |
| Intrón | No | Se elimina durante el splicing, aunque puede albergar señales reguladoras. |
| Promotor | No | Ayuda a iniciar la transcripción del gen. |
| Región intergénica | No | Separa genes y puede contener elementos que regulan su expresión. |
La tabla importa porque en genética clínica la pregunta correcta no suele ser “¿está en un gen o no?”, sino “¿afecta a la proteína, al procesamiento del ARN o a la regulación de la expresión?”. Y esa diferencia lleva directamente al siguiente punto: qué tipo de variante aparece en la región codificante y qué consecuencias puede tener.
Qué cambia cuando aparece una variante en la región codificante
Una variante en la parte codificante no equivale automáticamente a un problema grave. Yo la interpreto siempre según tres variables: qué tipo de cambio introduce, dónde cae dentro de la proteína y cuánto altera su función final. En medicina personalizada, esta lectura contextual pesa tanto como la propia mutación.
| Tipo de variante | Efecto habitual | Cuándo preocupa más |
|---|---|---|
| Sinónima | Cambia una base pero no el aminoácido. | Cuando altera el splicing, la estabilidad del ARNm o la eficiencia de traducción. |
| Missense | Sustituye un aminoácido por otro. | Cuando afecta a un dominio funcional o cambia mucho la química de la proteína. |
| Nonsense | Introduce un codón de parada prematuro. | Cuando genera una proteína truncada o desencadena degradación del ARNm. |
| Frameshift | Inserción o deleción que desplaza el marco de lectura. | Cuando altera todo el tramo posterior de la proteína. |
| Zona de empalme | Puede no tocar aminoácidos directamente, pero sí el procesamiento del ARN. | Cuando impide un splicing correcto y cambia el producto final. |
En una interpretación seria, yo no me quedaría con la etiqueta de la variante. Miraría el fenotipo, la frecuencia poblacional, el efecto sobre el transcript específico y, si existe, la evidencia funcional. Esto es especialmente importante porque una variante sinónima no es siempre inocua y una variante missense no es necesariamente patogénica. Con esa advertencia ya clara, toca revisar los errores que más distorsionan la lectura de un resultado genético.
Los errores que más distorsionan la lectura genética
El primero es pensar que un gen codificante determina por sí solo un rasgo complejo. En realidad, la mayoría de los rasgos humanos dependen de varios genes, del entorno y del momento biológico. El segundo error es asumir que todo lo no codificante es “ruido”: basta recordar que promotores, potenciadores, intrones y regiones intergénicas pueden cambiar la expresión del gen sin tocar la proteína.
También veo mucho la idea de que una variante sinónima “no hace nada”. A veces no hace nada relevante; otras sí altera el empalme o la traducción. El contexto manda. Y hay otro fallo todavía más frecuente en informes de laboratorio: leer una sola transcripción como si fuera la única versión del gen. Cuando un gen tiene varios isoformas, una misma variante puede caer dentro de la región codificante de un transcript y fuera de ella en otro, lo que cambia por completo la interpretación.
- Confundir gen con proteína y esperar una relación uno a uno.
- Ignorar que el efecto de una variante depende del tejido y del transcript analizado.
- Subestimar las regiones reguladoras por no codificar aminoácidos.
- Tomar una variante como patogénica sin revisar evidencia funcional o clínica.
Si uno corrige estos cuatro errores, la lectura genética gana mucha precisión. Y esa precisión es justo la que necesitamos para cerrar el tema con una idea útil y aplicable.
Lo que conviene recordar antes de interpretar una variante genética
Si me quedo con una sola idea, es esta: la región codificante explica la parte de la historia que termina en proteína, pero no explica por sí sola la función completa de un gen ni el impacto de una variante. Para interpretar bien un resultado hay que mirar la secuencia, el transcript, el splicing, la regulación y el fenotipo real de la persona.
- La secuencia codificante se entiende mejor dentro del gen completo, no aislada.
- El cambio más pequeño no siempre es el más inocuo.
- En clínica, el contexto biológico pesa tanto como la letra del ADN.
Yo lo resumiría así: entender una secuencia codificante sirve para leer la proteína, pero comprender de verdad una variante exige mirar más allá de la proteína. Ahí es donde la biología molecular deja de ser una lista de términos y empieza a ser una herramienta útil para investigación, diagnóstico y medicina personalizada.