Lo esencial sobre el alfabeto químico de los ácidos nucleicos
- Un nucleótido combina base, azúcar y fosfato; la base es la parte que aporta la identidad química.
- El ADN usa A, C, G y T; el ARN usa A, C, G y U.
- La complementariedad básica es A-T y G-C en ADN, y A-U y G-C en ARN.
- Las bases se agrupan en purinas y pirimidinas, una distinción que explica su forma y tamaño.
- Un cambio de una sola base puede no tener efecto, o puede alterar un codón, una proteína o una interpretación clínica.
- La lectura de estas letras es la base de la secuenciación, el diagnóstico genético y parte de la farmacogenética.
Qué son exactamente las bases nitrogenadas y por qué importan
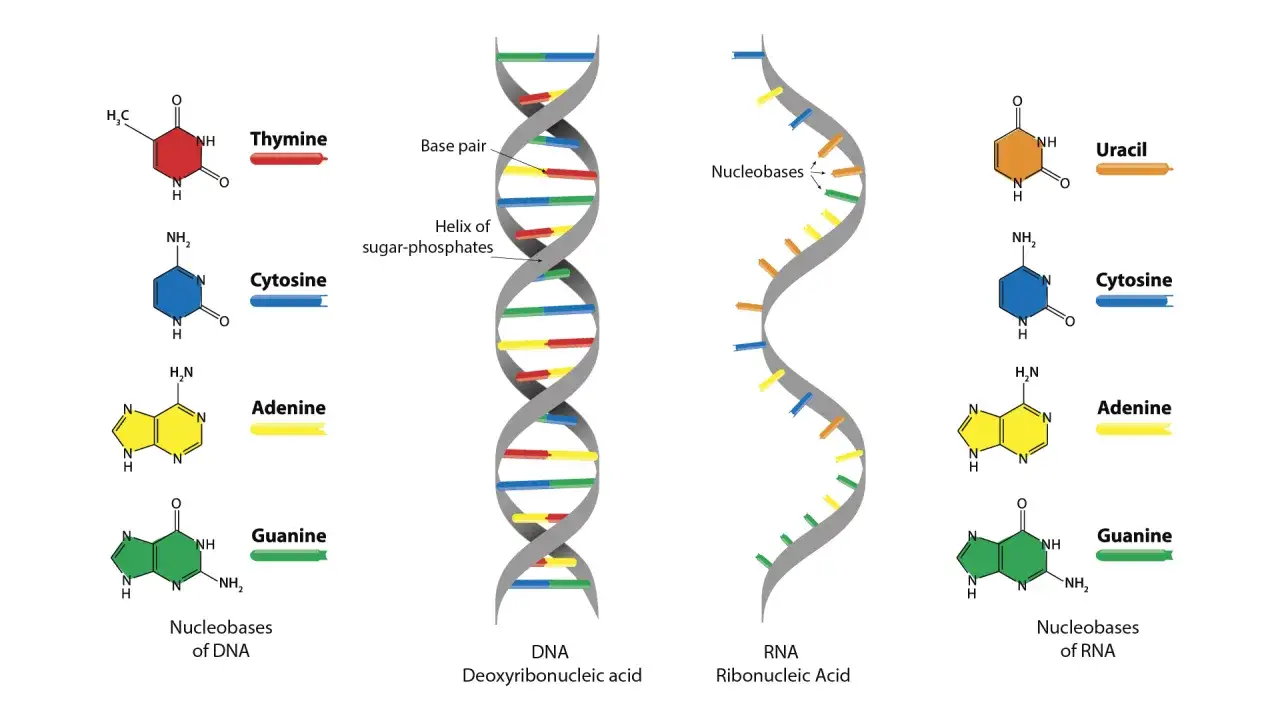
Yo suelo empezar por una distinción que evita muchos errores: base nitrogenada y nucleótido no son lo mismo. La base es la “letra”; el nucleótido es la unidad completa formada por base, azúcar y fosfato. En el ADN el azúcar es la desoxirribosa, mientras que en el ARN es la ribosa, y ese pequeño cambio ayuda a explicar por qué el ARN es más flexible y, por lo general, menos estable.
La ribosa del ARN conserva un grupo hidroxilo en el carbono 2', ausente en la desoxirribosa del ADN, y ese detalle aumenta su reactividad. Dicho de forma simple, el ADN está mejor preparado para guardar información durante mucho tiempo, mientras que el ARN está mejor preparado para usarla, moverla o regularla con rapidez.
La información genética no vive en una base aislada, sino en la secuencia completa. El esqueleto azúcar-fosfato da soporte, pero son las bases las que aportan el mensaje. Si yo tuviera que resumirlo en una sola frase: sin bases, hay estructura; con bases ordenadas, hay información.
Una vez que esta idea queda clara, ya tiene sentido ver qué letras usa cada molécula y por qué el ADN y el ARN no funcionan exactamente igual.
Qué bases usa cada ácido nucleico
Como resume el NHGRI, el ADN trabaja con cuatro bases: adenina (A), citosina (C), guanina (G) y timina (T), mientras que en el ARN la timina se sustituye por uracilo (U). Esa diferencia no es cosmética: el ADN está pensado para conservar información a largo plazo, y el ARN para usarla, transportarla o regularla con más rapidez.
| Molécula | Bases estándar | Azúcar | Estructura habitual | Función principal |
|---|---|---|---|---|
| ADN | A, C, G, T | Desoxirribosa | Doble cadena | Almacenar la información genética |
| ARN | A, C, G, U | Ribosa | Cadena simple, aunque puede plegarse | Expresar, transportar o modular la información |
La timina y el uracilo se parecen mucho, pero la timina lleva un grupo metilo adicional. Esa pequeña diferencia química ayuda a distinguir mejor el ADN del ARN y encaja con su papel biológico: el primero protege el archivo, el segundo lo pone en uso.
En biología real, algunos ARN llevan bases modificadas, sobre todo en moléculas como el ARN de transferencia o el ribosómico. Aun así, cuando se enseña la estructura básica de los ácidos nucleicos, el alfabeto estándar sigue siendo ese conjunto de cuatro letras por molécula. Con eso claro, el siguiente paso es entender cómo se reconocen entre sí.
Cómo se emparejan y qué significa la complementariedad
La complementariedad es el principio que permite que las dos hebras del ADN encajen como si fueran una cremallera química. Adenina se empareja con timina en ADN, o con uracilo en ARN; guanina se empareja con citosina. Esa regla no es arbitraria: responde a la geometría y a la química de las bases.
Los pares A-T y A-U forman dos puentes de hidrógeno; el par G-C forma tres. Por eso, las regiones ricas en G y C suelen ser algo más estables que las ricas en A y T. No significa que sean “mejores”, sino que resisten más al desenrollado cuando la célula copia el ADN o cuando necesita leer una región concreta.
La longitud de un gen se mide en pares de bases, y puede ir desde unos pocos cientos hasta decenas de miles. Ese dato importa porque un cambio pequeño dentro de una secuencia enorme puede pasar desapercibido o desencadenar un efecto muy concreto, según dónde ocurra. Ahí entra en juego la química interna de las bases, que se entiende mejor si las clasificamos.
Purinas y pirimidinas, la razón química detrás de su forma
A y G son purinas: tienen dos anillos fusionados. C, T y U son pirimidinas: tienen un solo anillo. Esta diferencia estructural no es un detalle de libro, sino la razón por la que las bases encajan con una geometría bastante constante dentro de la doble hélice.
| Grupo | Bases | Rasgo estructural | Por qué importa |
|---|---|---|---|
| Purinas | Adenina y guanina | Dos anillos | Son más grandes y siempre se emparejan con una pirimidina |
| Pirimidinas | Citosina, timina y uracilo | Un anillo | Ayudan a mantener un ancho uniforme en la doble hélice |
En otras palabras, la célula evita emparejar una purina con otra purina o una pirimidina con otra pirimidina porque la geometría resultante sería inestable. La combinación purina-pirimidina mantiene la estructura equilibrada y facilita que las enzimas reconozcan la secuencia con precisión. Desde aquí ya se ve mejor por qué un cambio de base puede tener consecuencias biológicas reales.
Qué ocurre cuando cambia una base en un gen
Una mutación puntual es el cambio de una sola base en la secuencia. No siempre es una mala noticia: algunas variantes son neutras, otras alteran la función de una proteína y unas pocas tienen efectos clínicos claros. Yo aquí sería prudente, porque interpretar una variante sin contexto es una forma rápida de equivocarse.
- Sustitución: una base se reemplaza por otra. Puede no cambiar el aminoácido, cambiarlo o introducir una señal de parada prematura.
- Inserción: se añade una base extra. Si no respeta el marco de lectura, puede desplazar la forma en que se leen los codones.
- Deleción: se pierde una base. También puede alterar el marco de lectura y modificar toda la proteína a partir de ese punto.
Los codones son grupos de tres nucleótidos que se leen en el ARN mensajero para construir proteínas. Por eso, un cambio mínimo a veces solo afecta a un aminoácido, pero en otras ocasiones cambia la proteína entera. Esa diferencia entre un efecto leve y uno serio es una de las razones por las que la secuenciación genética exige tanto rigor interpretativo.
Para mí, la idea más útil es esta: una variante no se interpreta por intuición, sino por evidencia. El gen concreto, el tipo de cambio, la frecuencia poblacional y el cuadro clínico deben encajar entre sí antes de sacar conclusiones.
Qué conviene retener para interpretar genes, variantes y pruebas genéticas
Si miro este tema desde la genética clínica, lo más importante no es memorizar letras sueltas, sino entender qué permite hacer su lectura. Las técnicas de secuenciación detectan variantes, los paneles genéticos buscan cambios en genes concretos y la medicina personalizada usa esa información para afinar diagnósticos y, en algunos casos, elegir mejor un tratamiento.
También conviene mantener una expectativa realista: no toda variante explica una enfermedad, y no toda diferencia entre dos personas tiene valor clínico. La interpretación correcta suele exigir combinar la secuencia con la historia familiar, los síntomas y el conocimiento funcional del gen. Esa forma de trabajar es más lenta que una respuesta automática, pero evita simplificaciones peligrosas.
Si te quedas con una sola idea, que sea esta: las bases no son un adorno químico del ADN y del ARN, sino la unidad mínima con la que la célula escribe, copia y corrige la información biológica. Entender cómo se ordenan y cómo se emparejan es el paso más corto para pasar de la teoría de los genes a una lectura útil de la biología molecular.